Scaling Maximo dans le cloud : fiabilité, disponibilité, reprise après sinistre et redondance
Erin Pierce
October 21, 2025
Les systèmes de gestion des actifs d'entreprise (EAM) tels qu'IBM Maximo sont essentiels pour les organisations gourmandes en actifs. Les temps d'arrêt, les pertes de données ou les performances insuffisantes peuvent entraîner d'importants risques opérationnels, de sécurité, réglementaires ou financiers. Alors que de plus en plus d'entreprises migrent Maximo vers des environnements cloud ou hybrides, ou optent pour une solution EAM cloud entièrement gérée, il est essentiel de comprendre comment optimiser la haute disponibilité, les garanties de disponibilité, la reprise après sinistre et la redondance.
Choisir le bon partenaire cloud devient une décision stratégique. Voici ce qu'il faut rechercher, les meilleures pratiques et la manière dont les offres cloud de Naviam répondent à ces exigences.
Haute disponibilité et redondance : considérations clés
La haute disponibilité (HA) signifie que votre environnement Maximo continue de fonctionner malgré les défaillances de composants, telles que les problèmes matériels, réseau, logiciels ou même au niveau du centre de données. Pour y parvenir, vous devez répondre aux questions suivantes :
Éliminez les points de défaillance uniques (SPOF)
Utilisez plusieurs instances de serveurs d'applications. Si un serveur tombe en panne, les autres continuent à servir les utilisateurs
Des équilibreurs de charge placés devant les serveurs Web ou les machines virtuelles virtuelles afin que le trafic soit distribué dynamiquement et redirigé en cas de défaillance d'un nœud
Serveurs Web redondants, équilibreurs de charge redondants, chemins réseau redondants
Redondance et clustering des bases de données
Des configurations de réplication de base de données, de clustering ou de haute disponibilité sont nécessaires. Maximo d'IBM prend en charge DB2 HADR, Oracle RAC, etc.
Utilisez des répliques de lecture le cas échéant (pour les rapports, le déchargement des lectures), mais assurez-vous de la durabilité et de la cohérence de l'écriture
Déployez dans plusieurs zones de disponibilité ou centres de données afin qu'une panne dans l'une d'entre elles n'entraîne pas l'arrêt du système
Des topologies active-passive ou active-active peuvent s'appliquer, en fonction de la continuité des activités et du budget. IBM propose des directives pour la haute disponibilité locale, les sites de reprise après sinistre passifs et les architectures hybrides
Systèmes de stockage et de fichiers résilients
Le stockage partagé (pièces jointes, fichiers d'intégration, journaux) doit être redondant et très durable
Assurez la réplication du stockage, la mise en miroir ou le stockage distribué afin d'éviter toute perte de données en cas de panne de disque ou de nœud de stockage
Les équilibreurs de charge doivent eux-mêmes être hautement disponibles (parfois en mode actif/en veille ou en cluster)
Correctifs, mises à niveau et maintenance de l'infrastructure
Même la maintenance planifiée doit être gérée de manière à ne pas dégrader la disponibilité de manière significative (mises à niveau continues, bleu/vert, etc.)
Les cycles de correctifs pour le système d'exploitation, les serveurs d'applications, les intergiciels et les fenêtres de maintenance des bases de données doivent être soigneusement planifiés
Sauvegarde et reprise après sinistre (DR)
La haute disponibilité permet de gérer de nombreuses défaillances, mais la reprise après sinistre consiste à se préparer à des défaillances graves, souvent au niveau du site : catastrophes naturelles, perte de centre de données, logiciels catastrophiques ou incidents d'infrastructure.
Les principaux éléments d'une stratégie de reprise après sinistre et de sauvegarde pour Maximo sont les suivants :
Définissez le RPO et le RTO
Objectif de point de restauration (RPO): la quantité de données récentes que vous êtes prêt à perdre (par exemple 15 minutes, 1 heure, etc.)
Objectif de temps de rétablissement (RTO): combien de temps il faudra pour remettre le système en ligne après une catastrophe
Sauvegardes fréquentes et fiables
Sauvegardes de base de données (sauvegardes complètes, incrémentielles, du journal des transactions) à une cadence suffisante pour respecter le RPO
Sauvegardes du système de fichiers/instantanés de stockage d'objets pour les pièces jointes, les fichiers de configuration, les journaux, etc.
Sauvegardes hors site (ou entre régions) pour vous protéger contre les catastrophes régionales
Environnements de secours
Veille froide (sauvegarde des données mais ne fonctionne pas sauf si nécessaire)
Veille chaude (certains services fonctionnent ; peuvent être promus)
Hot Standby ou réplication active (réplication en temps quasi réel, prête à prendre le relais presque immédiatement)
Procédures de test et de basculement
Les plans DR doivent être documentés mais également testés régulièrement
Les tests de basculement incluent la promotion de la mise en veille, de la précision, de la cohérence et de l'intégrité des données, et la garantie du fonctionnement des intégrations, des annuaires d'utilisateurs (LDAP/SAML), etc.
Correspondance entre versions et configurations
Le site DR ou l'environnement de secours doit correspondre à la production en termes de version logicielle, de configuration, de niveau de correctif, de réseau, etc. Sinon, la restauration risque d'être retardée ou problématique
Disponibilité, contrats de niveau de service (SLA) et surveillance
La sélection d'un fournisseur cloud ou d'un partenaire de services gérés pour Maximo implique la conclusion de contrats de niveau de service qui définissent la disponibilité, les performances, le support et les pénalités (ou crédits) si les objectifs ne sont pas atteints.
Points à surveiller :
Garantie de disponibilité en %
Les niveaux courants sont 99,9 % (« trois neuf »), 99,95 %, 99,99 % (« quatre neuf »), etc. Chaque incrément représente de grandes différences dans les temps d'arrêt autorisés.
Champ d'application du SLA
Qu'est-ce qui est exactement couvert (couche applicative/intergiciel/base de données/réseau/stockage)
Les dépendances externes sont-elles incluses (par exemple, les intégrations, les systèmes tiers) ?
Exclusions
Fenêtres de maintenance planifiées
Événements de force majeure
Problèmes causés par le client (par exemple, mauvaise configuration, code personnalisé)
Sanctions ou mesures correctives
Crédits de service, remboursements, etc. en cas de violation du SLA
Rapports et audits clairs sur les temps d'arrêt
Support et temps de réponse
Dans quelle mesure le fournisseur réagira-t-il rapidement aux incidents (niveaux de gravité, escalades d'urgence)
Disponibilité du service d'assistance (24 h/24, 7 j/7 et pendant les heures ouvrables)
Surveillance, alertes et rapports
Tableaux de bord de surveillance en temps réel
Alertes proactives lorsque les systèmes ou les bases de données sont soumis à des contraintes
Rapports périodiques sur la disponibilité et les mesures de performance
Compromis courants et préoccupations pratiques
La mise en place d'une solution de haute disponibilité et de reprise après sinistre comporte des coûts et de la complexité. Certaines décisions de compromis que les organisations doivent prendre :
Coût et disponibilité : Une redondance accrue, des déploiements multirégionaux, un RTO/RPO plus rapide sont autant de facteurs qui coûtent plus cher.
Complexité ou simplicité : Plus facile à utiliser, moins de pièces mobiles, mais elles augmentent les risques. Un plus grand nombre de nœuds et une plus grande dispersion géographique peuvent augmenter les modes de défaillance.
Cohérence des données par rapport à la latence : La réplication synchrone garantit une perte de données nulle ou minimale mais a tendance à ajouter de la latence ; la réplication asynchrone réduit la latence mais tolère certaines pertes de données.
Exigences réglementaires et de conformité : Certains secteurs exigent certains niveaux de disponibilité, de conservation des données, de séparation géographique, etc.
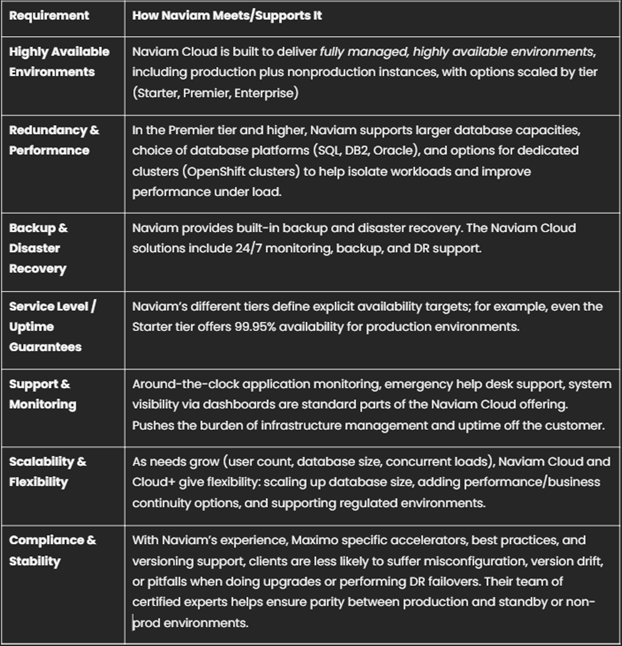
Comment la solution cloud de Naviam répond à ces besoins
Naviam est l'un des principaux fournisseurs dans le domaine Maximo/EAM, avec une expérience approfondie et des offres spécialement conçues pour répondre aux besoins de fiabilité, de disponibilité, de reprise après sinistre et de redondance pour les déploiements Maximo. Voici comment les fonctionnalités cloud de Naviam répondent aux besoins des entreprises.
Ce qu'il faut vérifier et les questions à poser avant de se lancer
Même lorsque vous choisissez un fournisseur de cloud tel que Naviam, il est judicieux de vérifier les détails. Voici les questions stratégiques à se poser :
Quelle est la portée exacte du SLA de disponibilité ? (Quelles couches sont inclues/exclues, où la redondance existe, etc.)
Quelles sont les mesures RPO et RTO en pratique, pour le niveau que vous avez choisi ?
Le site DR correspond-il à la production en termes de configuration et de version (système d'exploitation, intergiciel, application, intégrations) ? À quelle fréquence est-il mis à jour ?
À quelle fréquence les tests DR/Failover sont-ils effectués et quel est votre accès pour observer ou participer ?
En ce qui concerne la croissance/la mise à l'échelle (utilisateurs, transactions, pièces jointes), quelles sont les limites pratiques (taille de la base de données, simultanéité, charge) ? Comment les performances sont-elles contrôlées et améliorées ?
Quelles sont vos responsabilités (client ou fournisseur) en matière de sauvegardes/personnalisations/intégrations/configuration ?
Comment s'effectuent les mises à niveau, les correctifs et la maintenance ? Sont-ils roulants, bleus/verts, à faible impact ?
Quelles sont les compensations ou les crédits de service disponibles en cas de violation du SLA ?
La mise à l'échelle d'IBM Maximo dans le cloud ne se limite pas à la simple modification et à la modification des machines virtuelles. Pour bénéficier réellement des économies de coûts, de l'agilité et des performances, vous avez besoin d'un environnement conçu pour une haute disponibilité, une redondance et une résilience aux catastrophes, soutenu par des SLA solides, des sauvegardes et des restaurations robustes et un support expert.
La solution cloud de Naviam est bien positionnée pour les entreprises qui ont besoin d'une fiabilité élevée sans avoir à gérer elles-mêmes chaque couche et à faire peser une charge sur les équipes internes. Que vous commenciez à petite échelle ou que vous ayez besoin d'un fonctionnement réglementé de niveau entreprise 24 heures sur 24, 7 jours sur 7, Naviam propose des offres cloud hiérarchisées qui répondent à de nombreuses meilleures pratiques standard en matière de haute disponibilité et de reprise après sinistre dans l'espace Maximo.
Si vous envisagez de migrer Maximo vers le cloud ou si vous envisagez de passer à un fournisseur géré, il est intéressant de comparer votre risque actuel d'interruption de service ou de perte de données. Ce coût « d'assurance » est souvent sous-estimé par rapport au coût supplémentaire lié au passage à un partenaire cloud qui place la disponibilité, la redondance et la reprise après sinistre au cœur de son offre.


.avif)