Scaling Maximo in the Cloud: Reliability, Uptime, Disaster Recovery & Redundancy
Erin Pierce
October 21, 2025
Enterprise Asset Management (EAM) systems like IBM Maximo are mission‐critical for asset intensive organizations. Downtime, data loss, or underperformance can cascade into large operational, safety, regulatory, or financial risks. As more organizations migrate Maximo into cloud or hybrid cloud environments—or choose fully managed cloud EAM—understanding how to build for high availability, uptime guarantees, disaster recovery, and redundancy is essential.
Choosing the right cloud partner becomes a strategic decision. Here’s what to look for, best practices, and how Naviam’s cloud offerings align with those requirements.
High Availability & Redundancy: Key Considerations
High Availability (HA) means that your Maximo environment continues to operate despite component failures like hardware, network, software, or even data center level issues. To get there you need to address the following:
Eliminate Single Points of Failure (SPOFs)
Use multiple application server instances. If one server fails, the others continue serving users
Load‐balancers in front of web servers or JVMs so traffic is dynamically distributed and rerouted in case of a node failure
Redundant web servers, redundant load balancers, redundant network paths
Database Redundancy & Clustering
Database replication, clustering or high availability configurations are needed. IBM’s Maximo supports DB2 HADR, Oracle RAC, etc.
Use read replicas if appropriate (for reporting, offloading reads), but ensure write durability and consistency
Deploy across multiple availability zones or data centers so that an outage in one does not take down the system
Active-Passive or Active-Active topologies may apply, depending on business continuity and budget. IBM has guidelines for local HA, passive DR sites, and hybrid architectures
Resilient Storage and File Systems
Shared storage (attachments, integration files, logs) must be redundant and highly durable
Ensure storage replication, mirroring, or distributed storage so disk failures or storage node outages don’t lose data
Load balancers need to themselves be highly available (sometimes in active/standby or clustered fashion)
Infrastructure Patching, Upgrades & Maintenance
Even planned maintenance must be handled in ways that do not degrade availability significantly (rolling upgrades, blue/green, etc.)
Patch cycles for OS, application servers, middleware, and database maintenance windows must be carefully planned
Backup & Disaster Recovery (DR)
High availability handles many failures, but disaster recovery is about preparing for severe, often site-level failures: natural disasters, data center loss, catastrophic software or infrastructure incidents.
Key components of a DR & backup strategy for Maximo include:
Define RPO and RTO
Recovery Point Objective (RPO): how much recent data you are willing to lose (e.g. 15 minutes, 1 hour, etc.)
Recovery Time Objective (RTO): how long it will take to bring system back online after disaster
Frequent, Reliable Backups
Database backups (full, incremental, transaction log backups) at sufficient cadence to meet RPO
File system backups / object store snapshots for attachments, configuration files, logs etc.
Offsite backups (or cross-region) to protect against regional disasters
Standby Environments
Cold standby (backup data but not running unless needed)
Warm standby (some services running; can be promoted)
Hot standby or active replica (near real-time replication, ready to take over almost immediately)
Testing & Failover Procedures
DR plans must be documented but also tested regularly
Failover testing includes promotion of standby, data accuracy, consistency, integrity, and ensuring integrations, user directories (LDAP/SAML), etc. are working
Version / Configuration Matching
The DR site or standby environment should match production in software version, configuration, patch level, networking etc. Otherwise restore might be delayed or problematic
Uptime, Service Level Agreements (SLAs) & Monitoring
Selecting a cloud provider or managed service partner for Maximo implies entering into SLAs that define availability, performance, support, and the penalties (or credits) if targets aren’t met.
Things to pay attention to:
Uptime % Guarantee
Common tiers are 99.9% (“three nines”), 99.95%, 99.99% (“four nines”), etc. Each increment represents large differences in allowable downtime.
Scope of SLA
What exactly is covered (application layer/middleware/DB/network/storage)
Are external dependencies included (for example, integrations, 3rd party systems)?
How quickly will the provider respond to incidents (severity levels, emergency escalations)
Help desk availability (24/7 vs business hours)
Monitoring, Alerts & Reporting
Realtime monitoring dashboards
Proactive alerts when systems or databases are under stress
Periodic reports of uptime, performance metrics
Common Trade-Offs & Practical Concerns
Building for high availability and disaster recovery comes with costs and complexity. Some tradeoff decisions organizations need to make:
Cost vs Uptime: More redundancy, multi-region deployments, faster RTO/RPO all cost more.
Complexity vs Simplicity: Easier to operate fewer moving parts; but they increase risk. More nodes & more geographic dispersion can increase failure modes.
Data Consistency vs Latency: Synchronous replication ensures zero or minimal data loss but tends to add latency; asynchronous replication reduces latency but tolerates some data loss.
Regulatory / Compliance Requirements: Some industries mandate certain levels of availability, data retention, geographic separation etc.
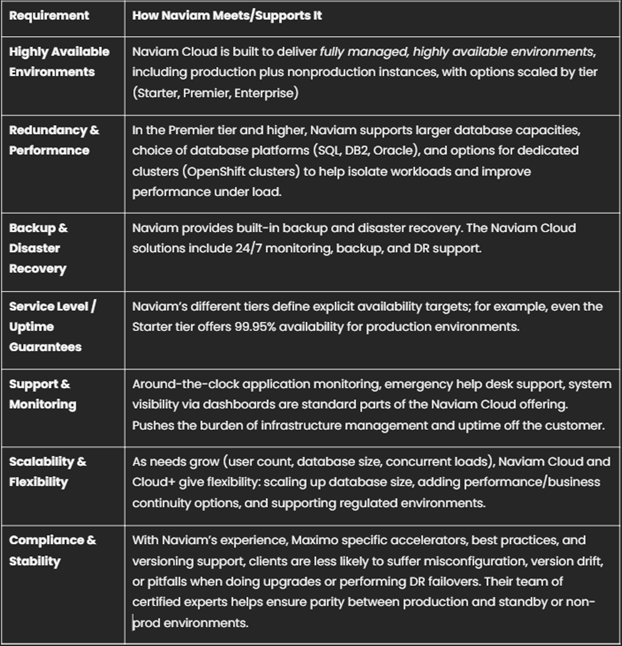
How Naviam’s Cloud Solution Addresses These Needs
Naviam is a leading provider in the Maximo/EAM space, with deep experience and offerings that are designed specifically to address reliability, uptime, DR, and redundancy for Maximo deployments. Here’s how Naviam’s cloud features map to what organizations need.
What to Check & Questions to Ask Before Going All-In
Even when choosing a cloud provider like Naviam, it’s wise to vet the details. Here are strategic questions to ask:
What is the exact scope of the uptime SLA? (Which layers are included/excluded, where redundancy exists, etc.)
What are the RPO and RTO metrics in practice, for your chosen tier?
Does the DR site match production in configuration and version (OS, middleware, application, integrations)? How often is it updated?
How often are DR/failover tests performed, and what is your access to observe or participate?
For growth/scaling (users, transactions, attachments), what are the practical limits (database size, concurrency, load)? How is performance monitored and improved?
What are your responsibilities (customer vs provider) in backups/customizations/integrations/configuration?
How are upgrades, patching, and maintenance done? Are they rolling, blue/green, low-impact?
What compensation or service credits exist if SLA is breached?
Scaling IBM Maximo in the cloud is about more than simply lifting and shifting on virtual machines. To truly benefit from cost savings, agility, and performance, you need an environment built for high availability, redundancy, and disaster resilience, backed with solid SLAs, robust backup & recovery, and expert support.
Naviam’s cloud solution is well-positioned for organizations that need strong reliability without the overhead of managing every layer themselves and placing a burden on internal teams. Whether you’re starting small or need enterprise-grade, regulated, 24/7 operation, Naviam offers tiered cloud offerings that map to many of the standard best practices for HA/DR in the Maximo space.
If you’re evaluating a move of Maximo into the cloud or considering switching to a managed provider, it’s worth comparing your current risk of downtime or data loss. That “insurance” cost is often underestimated against the incremental cost of moving to a cloud partner who makes availability, redundancy, and disaster recovery central to their offering.




.avif)