Escalar Maximo en la nube: confiabilidad, tiempo de actividad, recuperación ante desastres y redundancia
Erin Pierce
October 21, 2025
Los sistemas de gestión de activos empresariales (EAM) como IBM Maximo son de misión crítica para las organizaciones con uso intensivo de activos. El tiempo de inactividad, la pérdida de datos o el bajo rendimiento pueden derivar en grandes riesgos operativos, de seguridad, regulatorios o financieros. A medida que más organizaciones migran Maximo a entornos de nube o nube híbrida (o eligen un EAM en la nube totalmente gestionado), es fundamental comprender cómo crear soluciones que garanticen la alta disponibilidad, la garantía de tiempo de actividad, la recuperación ante desastres y la redundancia.
La elección del socio de nube adecuado se convierte en una decisión estratégica. Esto es lo que debe buscar, las mejores prácticas y cómo las ofertas de nube de Naviam se alinean con esos requisitos.
Alta disponibilidad y redundancia: consideraciones clave
La alta disponibilidad (HA) significa que su entorno Maximo continúa funcionando a pesar de las fallas de los componentes, como el hardware, la red, el software o incluso los problemas a nivel del centro de datos. Para llegar allí, debe abordar lo siguiente:
Elimine los puntos únicos de falla (SPOF)
Utilice varias instancias de servidor de aplicaciones. Si un servidor falla, los demás seguirán atendiendo a los usuarios
Equilibradores de carga frente a servidores web o JVM para que el tráfico se distribuya dinámicamente y se redirija en caso de que un nodo falle
Servidores web redundantes, balanceadores de carga redundantes, rutas de red redundantes
Redundancia y agrupamiento de bases de datos
Se necesitan configuraciones de replicación, agrupamiento en clústeres o alta disponibilidad de bases de datos. Maximo de IBM es compatible con DB2 HADR, Oracle RAC, etc.
Use réplicas de lectura si es apropiado (para generar informes, descargar lecturas), pero asegúrese de que la escritura sea duradera y uniforme
Infraestructura dispersa geográficamente, implementación multizonal o multirregional
Implemente en varias zonas de disponibilidad o centros de datos para que una interrupción en uno no interrumpa el sistema
Pueden aplicarse topologías activo-pasivo o activo-activo, según la continuidad del negocio y el presupuesto. IBM cuenta con directrices para la alta disponibilidad local, los sitios pasivos de recuperación ante desastres y las arquitecturas híbridas
Sistemas de almacenamiento y archivos resilientes
El almacenamiento compartido (archivos adjuntos, archivos de integración, registros) debe ser redundante y muy duradero
Garantice la replicación, la duplicación o el almacenamiento distribuido del almacenamiento para que las fallas en los discos o las interrupciones de los nodos de almacenamiento no pierdan datos
Equilibrio de red y carga
Redes redundantes, múltiples rutas de red, firewalls/enrutamiento redundantes
Los balanceadores de carga deben tener por sí mismos una alta disponibilidad (a veces en modo activo/en espera o agrupados en clústeres)
Parches, actualizaciones y mantenimiento de la infraestructura
Incluso el mantenimiento planificado debe gestionarse de manera que no degrade la disponibilidad de manera significativa (actualizaciones continuas, azul/verde, etc.)
Los ciclos de parches para las ventanas de mantenimiento del sistema operativo, los servidores de aplicaciones, el middleware y las bases de datos deben planificarse cuidadosamente
Respaldo y recuperación ante desastres (DR)
La alta disponibilidad gestiona muchos fallos, pero la recuperación ante desastres consiste en prepararse para los fallos graves, a menudo a nivel de sitio: desastres naturales, pérdidas de centros de datos, incidentes catastróficos de software o infraestructura.
Los componentes clave de una estrategia de DR y backup para Maximo incluyen:
Definir RPO y RTO
Objetivo de punto de recuperación (RPO): cuántos datos recientes está dispuesto a perder (por ejemplo, 15 minutos, 1 hora, etc.)
Objetivo de tiempo de recuperación (RTO): cuánto tiempo tardará en volver a funcionar el sistema después de un desastre
Respaldos frecuentes y confiables
Copias de seguridad de bases de datos (copias de seguridad completas, incrementales y del registro de transacciones) con una cadencia suficiente para cumplir con el RPO
Copias de seguridad del sistema de archivos/instantáneas del almacén de objetos para archivos adjuntos, archivos de configuración, registros, etc.
Respaldos externos (o interregionales) para protegerse contra los desastres regionales
Entornos en espera
Modo de espera en frío (copia de seguridad de los datos, pero no se ejecuta a menos que sea necesario)
Modo de espera activo (algunos servicios están en funcionamiento; se pueden promocionar)
Réplica activa o en espera (replicación casi en tiempo real, lista para tomar el control casi de inmediato)
Procedimientos de prueba y conmutación por error
Los planes de recuperación ante desastres deben documentarse, pero también deben probarse con regularidad
Las pruebas de conmutación por error incluyen la promoción del modo de espera, la precisión, la coherencia y la integridad de los datos y la garantía del funcionamiento de las integraciones, los directorios de usuarios (LDAP/SAML), etc.
Coincidencia entre versiones y configuraciones
El sitio de recuperación ante desastres o el entorno en espera deben coincidir con la producción en cuanto a la versión del software, la configuración, el nivel de parches, la red, etc. De lo contrario, la restauración podría retrasarse o resultar problemática
Tiempo de actividad, acuerdos de nivel de servicio (SLA) y supervisión
La selección de un proveedor de nube o un socio de servicios gestionados para Maximo implica establecer acuerdos de nivel de servicio que definan la disponibilidad, el rendimiento, el soporte y las penalizaciones (o créditos) si no se cumplen los objetivos.
Cosas a las que hay que prestar atención:
% de tiempo de actividad garantizado
Los niveles más comunes son el 99,9% («tres nueves»), el 99,95%, el 99,99% («cuatro nueves»), etc. Cada incremento representa grandes diferencias en cuanto al tiempo de inactividad permitido.
Alcance del SLA
Qué se cubre exactamente (capa de aplicación/middleware/base de datos, red/almacenamiento)
¿Se incluyen las dependencias externas (por ejemplo, integraciones, sistemas de terceros)?
Exclusiones
Ventanas de mantenimiento programadas
Eventos de fuerza mayor
Problemas causados por el cliente (por ejemplo, errores de configuración, código personalizado)
Sanciones o remedios
Créditos de servicio, reembolsos, etc. si se infringe el SLA
Informes y auditorías claros del tiempo de inactividad
Tiempos de soporte y respuesta
Qué tan rápido responderá el proveedor a los incidentes (niveles de gravedad, escalamientos de emergencia)
Disponibilidad del servicio de asistencia (24 horas al día, 7 días a la semana frente a
Monitorización, alertas e informes
Paneles de monitoreo en tiempo real
Alertas proactivas cuando los sistemas o las bases de datos están bajo estrés
Informes periódicos sobre el tiempo de actividad y las métricas de rendimiento
Compensaciones comunes y preocupaciones prácticas
La creación para la alta disponibilidad y la recuperación ante desastres conlleva costos y complejidad. Algunas decisiones compensatorias que las organizaciones deben tomar:
Costo frente a tiempo de actividad: Más redundancia, despliegues multirregionales y RTO/RPO más rápidos cuestan más.
Complejidad frente a simplicidad: Es más fácil operar con menos piezas móviles, pero aumentan el riesgo. Más nodos y una mayor dispersión geográfica pueden aumentar los modos de falla.
Coherencia de datos frente a latencia: La replicación sincrónica garantiza una pérdida de datos nula o mínima, pero tiende a añadir latencia; la replicación asincrónica reduce la latencia, pero tolera cierta pérdida de datos.
Requisitos reglamentarios/de cumplimiento: Algunas industrias exigen ciertos niveles de disponibilidad, retención de datos, separación geográfica, etc.
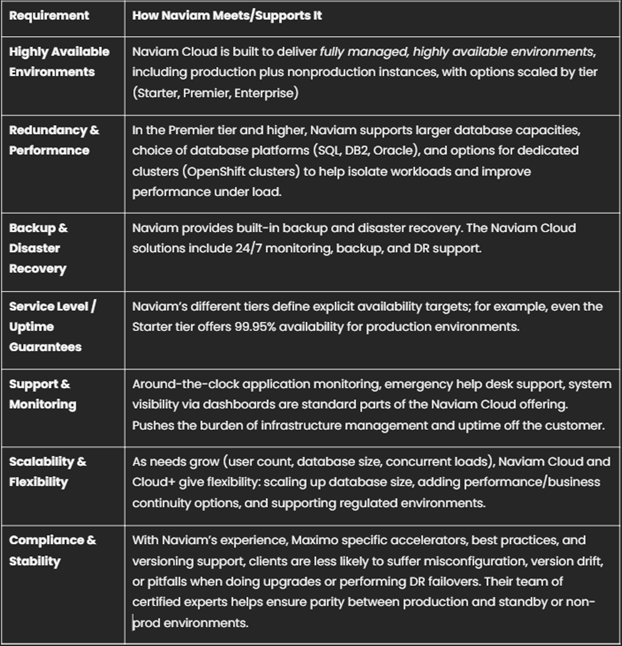
Cómo la solución en la nube de Naviam aborda estas necesidades
Naviam es un proveedor líder en el espacio de Maximo/EAM, con una amplia experiencia y ofertas diseñadas específicamente para abordar la confiabilidad, el tiempo de actividad, la recuperación ante desastres y la redundancia para las implementaciones de Maximo. Así es como las funciones de nube de Naviam se adaptan a las necesidades de las organizaciones.
Qué comprobar y preguntas que hacer antes de apostar por todo
Incluso a la hora de elegir un proveedor de servicios en la nube como Naviam, es aconsejable examinar los detalles. Estas son algunas preguntas estratégicas que debe hacerse:
¿Cuál es el alcance exacto del SLA de tiempo de actividad? (Qué capas se incluyen o excluyen, dónde existe redundancia, etc.)
¿Cuáles son las métricas de RPO y RTO en la práctica para el nivel elegido?
¿El sitio de DR coincide con la producción en cuanto a configuración y versión (sistema operativo, middleware, aplicación, integraciones)? ¿Con qué frecuencia se actualiza?
¿Con qué frecuencia se realizan las pruebas de recuperación ante desastres y conmutación por error y a qué tiene acceso para observarlas o participar?
Para el crecimiento/escalamiento (usuarios, transacciones, archivos adjuntos), ¿cuáles son los límites prácticos (tamaño de la base de datos, simultaneidad, carga)? ¿Cómo se monitorea y mejora el rendimiento?
¿Cuáles son sus responsabilidades (cliente o proveedor) en relación con las copias de seguridad, las personalizaciones, las integraciones y la configuración?
¿Cómo se realizan las actualizaciones, los parches y el mantenimiento? ¿Son rodantes, azules o verdes y de bajo impacto?
¿Qué compensación o créditos de servicio existen si se incumple el SLA?
Escalar IBM Maximo en la nube implica algo más que simplemente mover y mover máquinas virtuales. Para beneficiarse realmente del ahorro de costes, la agilidad y el rendimiento, necesita un entorno creado para ofrecer alta disponibilidad, redundancia y resiliencia ante desastres, respaldado por acuerdos de nivel de servicio sólidos, copias de seguridad y recuperación sólidas y soporte experto.
La solución en la nube de Naviam está bien posicionada para las organizaciones que necesitan una confiabilidad sólida sin la sobrecarga de administrar cada capa por sí mismas y representar una carga para los equipos internos. Ya sea que esté empezando con algo pequeño o necesite un funcionamiento de nivel empresarial regulado las 24 horas del día, los 7 días de la semana, Naviam ofrece ofertas de nube por niveles que se adaptan a muchas de las mejores prácticas estándar de alta disponibilidad y recuperación ante desastres en el ámbito de Maximo.
Si está evaluando el traslado de Maximo a la nube o está pensando en cambiarse a un proveedor gestionado, vale la pena comparar su riesgo actual de tiempo de inactividad o pérdida de datos. El coste del «seguro» suele subestimarse en comparación con el coste incremental que supone la migración a un socio de nube que hace de la disponibilidad, la redundancia y la recuperación ante desastres un aspecto fundamental de su oferta.


.avif)