Skalierung von Maximo in der Cloud: Zuverlässigkeit, Verfügbarkeit, Disaster Recovery und Redundanz
Erin Pierce
October 21, 2025
Enterprise Asset Management (EAM) -Systeme wie IBM Maximo sind für ressourcenintensive Unternehmen von entscheidender Bedeutung. Ausfallzeiten, Datenverlust oder Leistungsschwäche können große betriebliche, sicherheitstechnische, regulatorische oder finanzielle Risiken nach sich ziehen. Da immer mehr Unternehmen Maximo in Cloud- oder Hybrid-Cloud-Umgebungen migrieren oder sich für ein vollständig verwaltetes Cloud-EAM entscheiden, ist es unerlässlich zu wissen, wie Hochverfügbarkeit, Verfügbarkeitsgarantien, Disaster Recovery und Redundanz gewährleistet werden können.
Die Wahl des richtigen Cloud-Partners wird zu einer strategischen Entscheidung. Hier erfahren Sie, worauf Sie achten sollten, welche Best Practices es gibt und wie sich die Cloud-Angebote von Naviam an diesen Anforderungen orientieren.
Hochverfügbarkeit und Redundanz: Wichtige Überlegungen
Hochverfügbarkeit (HA) bedeutet, dass Ihre Maximo-Umgebung trotz Komponentenausfällen wie Hardware-, Netzwerk-, Software- oder sogar Rechenzentrumsproblemen weiterhin funktioniert. Um dorthin zu gelangen, müssen Sie Folgendes beachten:
Eliminieren Sie Single Points of Failure (SPOFs)
Verwenden Sie mehrere Anwendungsserverinstanzen. Wenn ein Server ausfällt, bedienen die anderen weiterhin Benutzer
Load-Balancer vor Webservern oder JVMs, sodass der Datenverkehr dynamisch verteilt und bei einem Node-Ausfall umgeleitet wird
Datenbankreplikations-, Clustering- oder Hochverfügbarkeitskonfigurationen sind erforderlich. Maximo von IBM unterstützt DB2 HADR, Oracle RAC usw.
Verwenden Sie gegebenenfalls Read Replicas (für Berichte, Auslagern von Lesevorgängen), achten Sie jedoch auf Dauerhaftigkeit und Konsistenz der Schreibvorgänge
Geografisch verteilte Infrastruktur//Mehrzonenbetrieb//Einsatz in mehreren Regionen
Stellen Sie es in mehreren Verfügbarkeitszonen oder Rechenzentren bereit, sodass ein Ausfall in einem Rechenzentrum das System nicht zum Erliegen bringt
Je nach Geschäftskontinuität und Budget können Aktiv-Passiv- oder Aktiv-Aktiv-Topologien gelten. IBM hat Richtlinien für lokale HA-, passive DR-Standorte und Hybridarchitekturen
Resiliente Speicher- und Dateisysteme
Der gemeinsam genutzte Speicher (Anhänge, Integrationsdateien, Protokolle) muss redundant und äußerst robust sein
Sorgen Sie für Speicherreplikation, Spiegelung oder verteilten Speicher, damit bei Festplattenausfällen oder Speicherknotenausfällen keine Daten verloren gehen
Netzwerk- und Lastenausgleich
Redundante Netzwerke, mehrere Netzwerkpfade, redundante Firewalls/Routing
Load Balancer müssen selbst hochverfügbar sein (manchmal im Aktiv-/Standby- oder Cluster-Modus)
Patching, Upgrades und Wartung der Infrastruktur
Selbst geplante Wartungsarbeiten müssen so durchgeführt werden, dass die Verfügbarkeit nicht wesentlich beeinträchtigt wird (fortlaufende Upgrades, blau/grün usw.)
Patch-Zyklen für Betriebssystem, Anwendungsserver, Middleware und Datenbankwartungsfenster müssen sorgfältig geplant werden
Sicherung und Notfallwiederherstellung (DR)
Hochverfügbarkeit bewältigt viele Ausfälle, aber bei Disaster Recovery geht es darum, sich auf schwerwiegende Ausfälle vorzubereiten, die häufig auf Standortebene auftreten: Naturkatastrophen, Verlust des Rechenzentrums, katastrophale Software- oder Infrastrukturvorfälle.
Zu den wichtigsten Komponenten einer DR- und Backup-Strategie für Maximo gehören:
Definieren Sie RPO und RTO
Wiederherstellungspunktziel (RPO): wie viele aktuelle Daten Sie bereit sind zu verlieren (z. B. 15 Minuten, 1 Stunde usw.)
Wiederherstellungszeitziel (RTO): wie lange es dauern wird, das System nach einer Katastrophe wieder online zu bringen
Häufige, zuverlässige Backups
Datenbanksicherungen (vollständige, inkrementelle Transaktionsprotokollsicherungen) in ausreichender Häufigkeit, um den RPO einzuhalten
Dateisystem-Backups/Objektspeicher-Snapshots für Anlagen, Konfigurationsdateien, Logs usw.
Offsite-Backups (oder regionsübergreifend) zum Schutz vor regionalen Katastrophen
Bereitschaftsumgebungen
Cold-Standby (Backup-Daten werden aber nicht ausgeführt, es sei denn, sie werden benötigt)
Warm-Standby (einige Dienste laufen; kann beworben werden)
Hot-Standby oder aktive Replikation (Replikation nahezu in Echtzeit, fast sofort einsatzbereit)
Test- und Failover-Verfahren
DR-Pläne müssen dokumentiert, aber auch regelmäßig getestet werden
Zu den Failover-Tests gehören die Förderung von Standby, Datengenauigkeit, Konsistenz und Integrität sowie die Sicherstellung, dass Integrationen, Benutzerverzeichnisse (LDAP/SAML) usw. funktionieren
Versions-/Konfigurationsabgleich
Der DR-Standort oder die Standby-Umgebung sollte in Bezug auf Softwareversion, Konfiguration, Patchlevel, Netzwerk usw. der Produktion entsprechen. Andernfalls kann es zu Verzögerungen oder Problemen bei der Wiederherstellung kommen
Verfügbarkeit, Service Level Agreements (SLAs) und Überwachung
Die Auswahl eines Cloud-Anbieters oder Managed-Service-Partners für Maximo setzt den Abschluss von SLAs voraus, die Verfügbarkeit, Leistung, Support und die Strafen (oder Gutschriften) definieren, wenn die Ziele nicht erreicht werden.
Dinge, auf die Sie achten sollten:
Verfügbarkeit in% garantiert
Übliche Stufen sind 99,9% („drei Neunen“), 99,95%, 99,99% („vier Neunen“) usw. Jede Erhöhung stellt große Unterschiede in den zulässigen Ausfallzeiten dar.
Umfang des SLA
Was genau wird abgedeckt (Anwendungsschicht/Middleware/DB/Netzwerk/Speicher)
Sind externe Abhängigkeiten enthalten (z. B. Integrationen, Systeme von Drittanbietern)?
Ausschlüsse
Zeitfenster für geplante Wartungsarbeiten
Ereignisse höherer Gewalt
Vom Kunden verursachte Probleme (z. B. Fehlkonfiguration, benutzerdefinierter Code)
Strafen oder Rechtsbehelfe
Servicegutschriften, Rückerstattungen usw., wenn das SLA verletzt wird
Klare Berichterstattung und Prüfung von Ausfallzeiten
Support und Reaktionszeiten
Wie schnell reagiert der Anbieter auf Vorfälle (Schweregrad, Notfalleskalationen)
Verfügbarkeit des Helpdesks (rund um die Uhr im Vergleich zu Geschäftszeiten)
Überwachung, Warnmeldungen und Berichterstattung
Dashboards zur Echtzeitüberwachung
Proaktive Warnmeldungen, wenn Systeme oder Datenbanken unter Stress stehen
Regelmäßige Berichte über Verfügbarkeit und Leistungskennzahlen
Allgemeine Kompromisse und praktische Bedenken
Die Entwicklung auf Hochverfügbarkeit und Disaster Recovery ist mit Kosten und Komplexität verbunden. Einige Kompromissentscheidungen, die Unternehmen treffen müssen:
Kosten im Vergleich zu Verfügbarkeit: Mehr Redundanz, Bereitstellungen in mehreren Regionen, schnelleres RTO/RPO kosten mehr.
Komplexität versus Einfachheit: Es ist einfacher, weniger bewegliche Teile zu bedienen, aber sie erhöhen das Risiko. Mehr Knoten und eine größere geografische Streuung können die Ausfallwahrscheinlichkeit erhöhen.
Datenkonsistenz im Vergleich zu Latenz: Die synchrone Replikation gewährleistet keinen oder nur minimalen Datenverlust, erhöht jedoch tendenziell die Latenz. Die asynchrone Replikation reduziert die Latenz, toleriert jedoch einen gewissen Datenverlust.
Behörden/ Compliance-Anforderungen: Einige Branchen schreiben ein bestimmtes Maß an Verfügbarkeit, Datenspeicherung, geografische Trennung usw. vor.
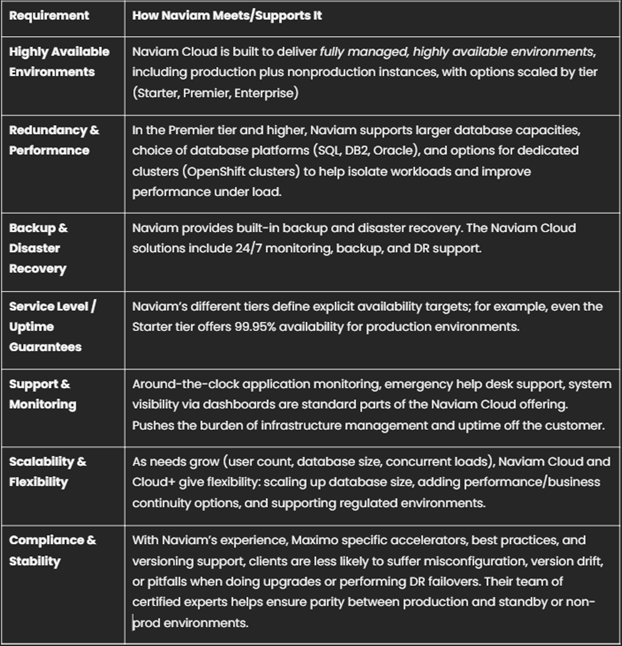
Wie die Cloud-Lösung von Naviam diese Anforderungen erfüllt
Naviam ist ein führender Anbieter im Maximo/EAM-Bereich mit umfassender Erfahrung und Angeboten, die speziell auf Zuverlässigkeit, Verfügbarkeit, DR und Redundanz für Maximo-Bereitstellungen zugeschnitten sind. So passen die Cloud-Funktionen von Naviam zu den Bedürfnissen von Unternehmen.
Was Sie überprüfen sollten und welche Fragen Sie stellen sollten, bevor Sie All-In gehen
Selbst wenn Sie sich für einen Cloud-Anbieter wie Naviam entscheiden, ist es ratsam, die Details zu überprüfen. Hier sind strategische Fragen, die Sie sich stellen sollten:
Was ist der genaue Umfang des Uptime-SLA? (Welche Schichten sind eingeschlossen/ausgeschlossen, wo Redundanz besteht usw.)
Was sind die RPO- und RTO-Metriken in der Praxis für die von Ihnen gewählte Stufe?
Entspricht der DR-Standort in Konfiguration und Version (Betriebssystem, Middleware, Anwendung, Integrationen) der Produktion? Wie oft wird sie aktualisiert?
Wie oft werden DR/Failover-Tests durchgeführt und welche Rechte haben Sie zu beobachten oder daran teilzunehmen?
Was sind die praktischen Grenzen (Datenbankgröße, Parallelität, Auslastung) für Wachstum/Skalierung (Benutzer, Transaktionen, Anlagen)? Wie wird die Leistung überwacht und verbessert?
Was sind Ihre Aufgaben (Kunde oder Anbieter) in Bezug auf Backups/Anpassungen/Integrationen/Konfiguration?
Wie werden Upgrades, Patches und Wartungsarbeiten durchgeführt? Sind sie rollend, blau/grün, haben sie geringe Auswirkungen?
Welche Entschädigung oder Servicegutschriften gibt es, wenn das SLA verletzt wird?
Bei der Skalierung von IBM Maximo in der Cloud geht es um mehr als nur um das Heben und Verschieben auf virtuellen Maschinen. Um wirklich von Kosteneinsparungen, Agilität und Leistung profitieren zu können, benötigen Sie eine Umgebung, die auf Hochverfügbarkeit, Redundanz und Notfallsicherheit ausgelegt ist und die durch solide SLAs, robuste Backup- und Recovery-Prozesse sowie fachkundigen Support unterstützt wird.
Die Cloud-Lösung von Naviam ist gut positioniert für Unternehmen, die eine hohe Zuverlässigkeit benötigen, ohne jede Ebene selbst verwalten zu müssen und interne Teams zu belasten. Ganz gleich, ob Sie klein anfangen oder einen regulierten Betrieb rund um die Uhr auf Unternehmensebene benötigen, Naviam bietet mehrstufige Cloud-Angebote, die vielen der bewährten Standardmethoden für HA/DR im Maximo-Bereich entsprechen.
Wenn Sie eine Migration von Maximo in die Cloud in Betracht ziehen oder erwägen, zu einem verwalteten Anbieter zu wechseln, lohnt es sich, Ihr aktuelles Risiko von Ausfallzeiten oder Datenverlusten zu vergleichen. Diese „Versicherungskosten“ werden oft im Vergleich zu den zusätzlichen Kosten für den Wechsel zu einem Cloud-Partner unterschätzt, der Verfügbarkeit, Redundanz und Disaster Recovery in den Mittelpunkt seines Angebots stellt.



.avif)