Maximo opschalen in de cloud: betrouwbaarheid, uptime, noodherstel en redundantie
Erin Pierce
October 21, 2025
Enterprise Asset Management (EAM) -systemen zoals IBM Maximo zijn van cruciaal belang voor organisaties die veel bedrijfsmiddelen gebruiken. Downtime, gegevensverlies of ondermaatse prestaties kunnen leiden tot grote operationele, veiligheids-, regelgevings- of financiële risico's. Naarmate meer organisaties Maximo migreren naar cloud- of hybride cloudomgevingen, of kiezen voor een volledig beheerd cloud-EAM, is het essentieel om te weten hoe ze kunnen bouwen voor hoge beschikbaarheid, uptime-garanties, noodherstel en redundantie.
Het kiezen van de juiste cloudpartner wordt een strategische beslissing. Hier leest u waar u op moet letten, wat de beste werkwijzen zijn en hoe het cloudaanbod van Naviam aan deze vereisten voldoet.
Hoge beschikbaarheid en redundantie: belangrijke overwegingen
High Availability (HA) betekent dat uw Maximo-omgeving blijft functioneren ondanks defecte onderdelen zoals hardware, netwerk, software of zelfs problemen op datacenterniveau. Om daar te komen moet je het volgende aanpakken:
Elimineer Single Points of Failure (SPOFs)
Gebruik meerdere instanties van de toepassingsserver. Als een server uitvalt, blijven de andere gebruikers bedienen
Load‐balancers voor webservers of JVM's, zodat het verkeer dynamisch wordt verdeeld en omgeleid in geval van een storing in het knooppunt
Er zijn configuraties voor databasereplicatie, clustering of hoge beschikbaarheid nodig. IBM's Maximo ondersteunt DB2 HADR, Oracle RAC, enz.
Gebruik indien nodig leesreplica's (voor rapportage, het uitladen van leesbewerkingen), maar zorg voor duurzaamheid en consistentie van het schrijven
Geografisch verspreide infrastructuur, implementatie in meerdere zones en meerdere regio's
Implementeer in meerdere beschikbaarheidszones of datacenters, zodat een storing in één zone het systeem niet uitvalt
Actief-passieve of actief-actieve topologieën kunnen van toepassing zijn, afhankelijk van de bedrijfscontinuïteit en het budget. IBM heeft richtlijnen voor lokale HA-, passieve DR-sites en hybride architecturen
Veerkrachtige opslag- en bestandssystemen
Gedeelde opslag (bijlagen, integratiebestanden, logboeken) moet redundant en zeer duurzaam zijn
Zorg voor opslagreplicatie, spiegeling of gedistribueerde opslag, zodat schijfstoringen of uitval van opslagknooppunten geen gegevens verloren gaan
Load balancers moeten zelf in hoge mate beschikbaar zijn (soms in actief/stand-by of geclusterd)
Patching, upgrades en onderhoud van de infrastructuur
Zelfs gepland onderhoud moet worden uitgevoerd op manieren die de beschikbaarheid niet significant verminderen (doorlopende upgrades, blauw/groen, enz.)
Patchcycli voor besturingssystemen, toepassingsservers, middleware en database-onderhoudsvensters moeten zorgvuldig worden gepland
Back-up en noodherstel (DR)
Hoge beschikbaarheid zorgt voor veel storingen, maar bij noodherstel gaat het erom dat u zich voorbereidt op ernstige storingen, vaak op locatieniveau: natuurrampen, verlies van datacenters, catastrofale software- of infrastructuurincidenten.
De belangrijkste componenten van een DR- en back-upstrategie voor Maximo zijn onder meer:
Definieer RPO en RTO
Herstelpuntdoelstelling (RPO): hoeveel recente gegevens u bereid bent te verliezen (bijvoorbeeld 15 minuten, 1 uur, enz.)
Doelstelling voor hersteltijd (RTO): hoe lang duurt het om het systeem weer online te brengen na een ramp
Regelmatige, betrouwbare back-ups
Databaseback-ups (volledige, incrementele back-ups van transactielogboeken) met voldoende cadans om aan de RPO te voldoen
Back-ups van het bestandssysteem/momentopnamen van objecten voor bijlagen, configuratiebestanden, logboeken, enz.
Externe back-ups (of regiooverschrijdend) ter bescherming tegen regionale rampen
Standby-omgevingen
Koude stand-by (back-up van gegevens, maar niet actief, tenzij nodig)
Warme stand-by (sommige services zijn actief; kan worden bevorderd)
Hot stand-by of actieve replica (bijna realtime replicatie, vrijwel onmiddellijk klaar om over te nemen)
Test- en failover-procedures
DR-plannen moeten worden gedocumenteerd, maar ook regelmatig worden getest
Failover-tests omvatten het bevorderen van stand-by, gegevensnauwkeurigheid, consistentie en integriteit, en ervoor zorgen dat integraties, gebruikersmappen (LDAP/SAML), enz. werken
Afstemming van versie/configuratie
De DR-site of standby-omgeving moet overeenkomen met de productie wat betreft softwareversie, configuratie, patchniveau, netwerk, enz. Anders kan het herstel vertraagd of problematisch zijn
Uptime, Service Level Agreements (SLA's) en monitoring
Als u een cloudprovider of managed servicepartner voor Maximo selecteert, moet u SLA's afsluiten waarin de beschikbaarheid, prestaties, ondersteuning en de boetes (of kredieten) worden bepaald als de doelstellingen niet worden gehaald.
Dingen om op te letten:
Uptime% garantie
Veel voorkomende niveaus zijn 99,9% („drie negens”), 99,95%, 99,99% („vier negens”), enz. Elke stap vertegenwoordigt grote verschillen in toegestane uitvaltijd.
Toepassingsgebied van de SLA
Wat komt er precies aan bod (applicatielaag/middleware/DB/Network/Storage)
Zijn externe afhankelijkheden inbegrepen (bijvoorbeeld integraties, systemen van derden)?
Uitsluitingen
Vensters voor gepland onderhoud
Gebeurtenissen van overmacht
Door de klant veroorzaakte problemen (bijv. verkeerde configuratie, aangepaste code)
Sancties of rechtsmiddelen
Servicekredieten, terugbetalingen, enz. als de SLA wordt geschonden
Duidelijke rapportage en controle van downtime
Ondersteunings- en reactietijden
Hoe snel reageert de provider op incidenten (ernstniveaus, escalaties in noodsituaties)
Beschikbaarheid van de helpdesk (24/7 versus kantooruren)
Monitoring, waarschuwingen en rapportage
Dashboards voor realtime monitoring
Proactieve waarschuwingen wanneer systemen of databases onder druk staan
Periodieke rapporten over uptime, prestatiestatistieken
Veelvoorkomende afwegingen en praktische problemen
Bouwen voor hoge beschikbaarheid en noodherstel brengt kosten en complexiteit met zich mee. Sommige afwegingen die organisaties moeten nemen:
Kosten versus uptime: Meer redundantie, implementaties in meerdere regio's, snellere RTO/RPO kosten allemaal meer.
Complexiteit versus eenvoud: Makkelijker te bedienen, minder bewegende onderdelen; maar ze verhogen het risico. Meer knooppunten en meer geografische spreiding kunnen de storingsmodi vergroten.
Consistentie van gegevens versus latentie: Synchrone replicatie zorgt voor nul of minimaal gegevensverlies, maar heeft de neiging om latentie toe te voegen; asynchrone replicatie vermindert de latentie, maar tolereert enig gegevensverlies.
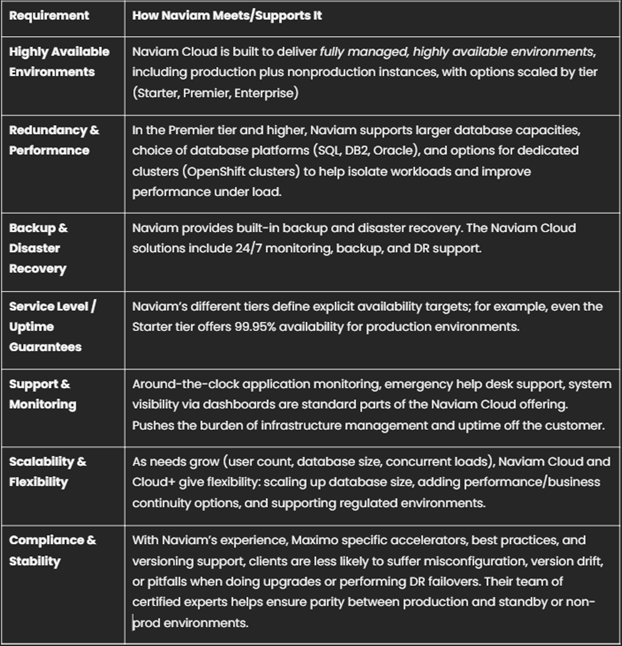
Hoe de cloudoplossing van Naviam aan deze behoeften voldoet
Naviam is een toonaangevende leverancier op het gebied van Maximo/EAM, met uitgebreide ervaring en aanbiedingen die specifiek zijn ontworpen voor betrouwbaarheid, uptime, DR en redundantie voor Maximo-implementaties. Zo komen de cloudfuncties van Naviam overeen met wat organisaties nodig hebben.
Wat u moet controleren en vragen die u moet stellen voordat u all-in gaat
Zelfs als je kiest voor een cloudprovider zoals Naviam, is het verstandig om de details te controleren. Hier zijn strategische vragen die je kunt stellen:
Wat is de exacte omvang van de uptime SLA? (Welke lagen zijn inbegrepen/uitgesloten, waar redundantie bestaat, enz.)
Wat zijn de RPO- en RTO-statistieken in de praktijk voor het door u gekozen niveau?
Komt de DR-site qua configuratie en versie overeen met de productie (besturingssysteem, middleware, applicatie, integraties)? Hoe vaak wordt het bijgewerkt?
Hoe vaak worden DR/failover-tests uitgevoerd en wat is uw toegang om te observeren of deel te nemen?
Wat zijn de praktische limieten voor groei/schaalvergroting (gebruikers, transacties, bijlagen) (databasegrootte, gelijktijdigheid, belasting)? Hoe worden de prestaties gecontroleerd en verbeterd?
Wat zijn uw verantwoordelijkheden (klant versus provider) bij backups/aanpassingen/integraties/configuratie?
Hoe worden upgrades, patches en onderhoud uitgevoerd? Zijn ze rollend, blauw/groen, hebben ze weinig impact?
Welke vergoedingen of servicekredieten zijn er als de SLA wordt geschonden?
Het opschalen van IBM Maximo in de cloud gaat over meer dan alleen het verbeteren en verschuiven van virtuele machines. Om echt te profiteren van kostenbesparingen, flexibiliteit en prestaties hebt u een omgeving nodig die is gebouwd voor hoge beschikbaarheid, redundantie en noodbestendigheid, ondersteund door solide SLA's, robuuste back-up en herstel en deskundige ondersteuning.
De cloudoplossing van Naviam is goed gepositioneerd voor organisaties die behoefte hebben aan een sterke betrouwbaarheid zonder de overhead om elke laag zelf te beheren en de interne teams te belasten. Of u nu klein begint of behoefte hebt aan een gereguleerde bedrijfsvoering die 24/7 beschikbaar is, Naviam biedt gelaagde cloudaanbiedingen die voldoen aan veel van de standaard best practices voor HA/DR in de Maximo-sector.
Als u een overstap van Maximo naar de cloud overweegt of overweegt over te stappen naar een beheerde provider, is het de moeite waard om uw huidige risico op downtime of gegevensverlies te vergelijken. Die „" verzekeringskosten "” worden vaak onderschat ten opzichte van de incrementele kosten van de overstap naar een cloudpartner die beschikbaarheid, redundantie en noodherstel centraal stelt in hun aanbod.”


.avif)